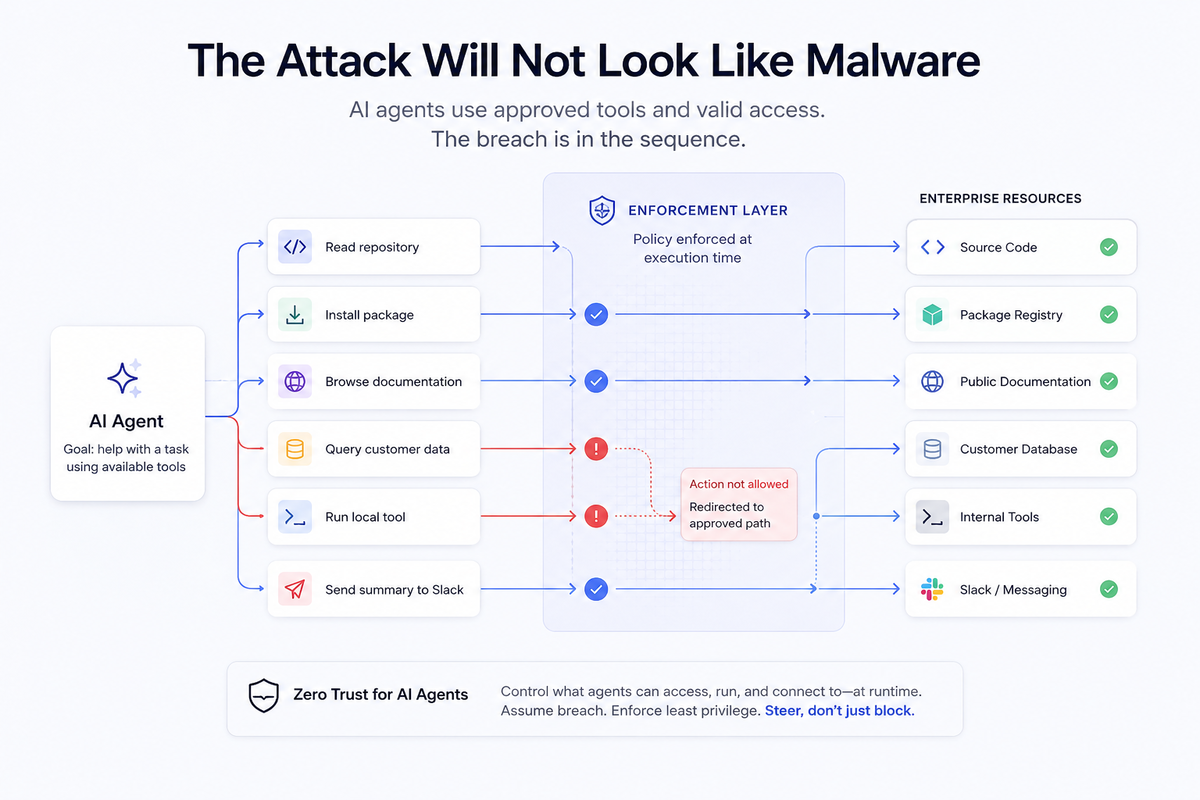
An AI agent does not need malware to cause damage. The individual steps may all look legitimate. The breach is in the sequence.
An AI agent does not need malware to cause damage. It can use approved tools, valid credentials, normal APIs, an existing browser session, a package manager it is allowed to call, a repository it is allowed to read, or a customer record it is allowed to summarize.
That is what makes securing agents different. The individual steps may all look legitimate. The breach is in the sequence.
Anthropic's Zero Trust for AI Agents makes this shift very clear. Prompt instructions are not enough. Tool permissions inside the agent are not enough. Logs after the fact are not enough. When an agent can read files, call APIs, use credentials, browse internal systems, and chain tools together, the control point cannot live only inside the thing being controlled.
You need enforcement outside the agent. That is the plane we are building at Canyon Road.
The agent is not stealing access. It is using access that already exists.
Most enterprise security programs are still trained to look for malware, suspicious binaries, stolen credentials, unusual logins, or known bad infrastructure. All of that still matters, but it does not fully describe the risk created by agents.
A coding agent can read a repo, inspect environment variables, call a package manager, open a connection, write files, and run tests. A support agent can read customer records, summarize them, and send a message. A desktop agent can browse an internal app, copy data, invoke a local tool, and upload the result somewhere else.
In each case, the tools may be legitimate. The credentials may be valid. The operating system may not be exploited. The agent is already in the environment, operating with access that was intentionally granted.
The problem starts when untrusted input, a poisoned tool result, a malicious MCP server, or a compromised workflow pushes that agent into using its access in a way nobody intended. Traditional host-centric monitoring can miss this because it is often looking for the wrong shape of attack. It looks for malware, but there is none. It checks whether the credentials are valid, and they are. It sees approved tools being used, but not necessarily the risk created by the combination.
For agents, the security question is no longer only which binary is running or which user is logged in. It is what operation is being attempted, by which agent, against which resource, through which tool, and with what blast radius.
That requires a layer that understands actions, not just identities.
The useful test: impossible, not tedious
One of the best ideas in Anthropic's framework is the test it gives for controls: does the control make the attack impossible, or does it only make it tedious?
That distinction matters more for agents than it did for traditional human-driven workflows. A human attacker has fatigue, cost, and patience limits. An agent can retry, rephrase, split a task into smaller steps, and keep looking for another path at machine speed and low marginal cost.
That means friction ages badly. Rate limits, extra hops, non-standard ports, warning banners, "be careful" prompts, and agent-managed permission files can all be useful, but they are not enough by themselves. They may make the attack more annoying. They do not necessarily remove the capability.
The controls that survive are the ones that actually take something away: no credential, no network path, no write permission, no file mount, no syscall, no way to send the data out.
That is the difference between asking an agent not to do something and making it unable to do it.
In-agent controls are necessary, but not sufficient
This is not an argument against agent-level controls. Allowlists, settings files, hooks, MCP configuration, permission prompts, and human approvals are all useful. They should exist.
But they are the first front. They live inside the agent runtime and depend on the agent framework, local configuration, and surrounding environment remaining trustworthy.
Zero Trust starts from a different assumption. Assume the prompt was injected. Assume the tool result was poisoned. Assume the MCP server was malicious. Assume the agent ignored the instruction. Assume the credential leaked.
Then ask what still stops it.
Anthropic's framework answers that directly. Tool access has to be controlled at the agent level and outside the agent level, in case the agent or its environment is compromised.
That second front is not a prompt, and it is not a setting the agent can read or modify. It is enforcement outside the agent's reasoning loop: runtime isolation, filesystem and network policy, credential mediation, tool and MCP policy enforced before execution, approvals the agent cannot bypass, and audit the agent cannot rewrite.
The important property is that the control point does not require the agent to cooperate.
Agents need their own enforcement plane
Enterprises already have security models for users, endpoints, applications, workloads, and networks. Agents cut across all of them.
An agent is not just an application. It is an actor with tools, memory, credentials, and the ability to chain steps in ways the original developers never explicitly encoded. That is why agents need a dedicated enforcement plane.
At Canyon Road, we think about this in three parts: AgentSH for runtime enforcement, Beacon for endpoint enforcement, and Watchtower for centralized governance.
AgentSH enforces at the runtime
AgentSH enforces policy where agents execute: shells, sandboxes, containers, build environments, cloud workloads, coding agents, and task runners.
This is where policy becomes concrete. Can the agent read this file? Can it write outside the project? Can it execute this binary? Can it open this socket? Can it reach this secret? Can it call this MCP tool?
Those decisions cannot reliably be left to a prompt. They need to be made at execution time, outside the agent, before the action happens.
For example, a coding agent can be allowed to run tests and read the repository, while still being blocked from reading .env, opening arbitrary outbound connections, invoking unapproved MCP tools, or writing outside the workspace without approval. The agent can still do useful work, but the blast radius is different.
The agent proposes the action. Policy decides whether it happens.
Beacon enforces the endpoint
A lot of agentic work has moved onto laptops: Claude Code, Claude Desktop, Cursor, VS Code, local MCP servers, browser automation, local CLIs, and internal tools.
That environment is messy and full of real access. Human credentials, browser sessions, SSH keys, cloud CLIs, source code, Slack, Gmail, and internal dashboards are all available on the endpoint. From the agent's point of view, the desktop is one large tool surface.
Beacon gives organizations enforcement and visibility over what those agents actually do. Which process made the request? Which file was read? Which domain did it reach? Was the action expected? Should it be approved, blocked, logged, or redirected?
The endpoint is where valid credentials become dangerous, because the agent is not stealing access. It is using access that already exists.
Watchtower governs the enforcement plane
AgentSH and Beacon apply policy at the runtime and endpoint. Watchtower is how organizations govern that enforcement across the fleet.
Watchtower manages baselines, distributes policy to enforcement points, collects audit, exports to the SIEM, and gives security teams visibility across agents and environments. Its most important role under pressure is the policy overlay.
When a new vulnerability lands and there is no patch yet, or when the patch cannot be deployed immediately, Watchtower can distribute an overlay that constrains the affected behavior at the enforcement layer. AgentSH and Beacon apply that overlay, and the exploit path can be closed across the fleet before the upstream fix is available everywhere.
That is virtual patching for agents.
This matters because the response window is getting shorter. Exploits can appear within hours of a patch, while many organizations still need days or weeks to validate and deploy fixes across every dependency, base image, extension, agent runtime, and laptop. The enforcement plane gives security teams a place to act immediately.
Watchtower is also where this becomes manageable over time. Zero Trust is not a static configuration. As agent behavior changes, the governance layer needs to understand normal patterns, tune policy, distribute updates, and keep the whole system observable.
The enforcement layer should steer, not just deny
Hard denial is sometimes the right answer, but it is not always the best one.
When an agent tries a disallowed action and receives only a generic error, it may not stop. It may retry, rephrase, or find another path to the same goal. That can burn time and tokens, corrupt state, or push the agent into a loop.
The enforcement layer should be able to steer, not only block.
AgentSH and Beacon can intercept an action and return a controlled response that explains the boundary and gives the agent a safer path forward. For example, if the agent reaches for a secret it should not touch, or starts down a path that would end in a loop, the enforcement layer can tell it that the action is not allowed and indicate how to continue within policy.
That is different from prompt-based instruction. The steering comes from the control point outside the agent's reasoning loop, with authority the agent does not get to bypass.
The same action channel that can be abused by a poisoned web page, malicious tool result, or compromised MCP server can also be used by the enforcement layer to keep the agent on rails. The difference is provenance. One is untrusted content trying to hijack the agent. The other is policy enforced outside the agent.
The goal is not only to stop one bad action. It is to prevent the cascade of bad actions that would have followed.
The floor moved
Anthropic's framework treats sandboxed execution as table stakes for agents handling untrusted input. That matters because nearly every useful agent handles untrusted input: web pages, documents, emails, tickets, repositories, packages, tool results, and MCP responses.
The floor moved.
The old question was how to write a safer prompt. That is still useful, but it is no longer the main enterprise question. The better question is: when the agent is compromised, confused, over-permissioned, or simply wrong, what still holds?
The answer is not one control. It is a stack: identity for the agent, least agency for its tools, short-lived credentials, runtime isolation, endpoint control, network egress control, approvals for risky actions, immutable audit, and centralized policy that can change faster than the threat.
AgentSH, Beacon, and Watchtower are our version of that stack: runtime, endpoint, and fleet.
Anthropic defined the framework. The enforcement plane is what makes it operational.
Zero Trust for agents starts when permission moves out of the prompt and into the execution path.
Thanks to Jesse Robbins for reviewing an earlier draft of this post. Jesse has been researching sandboxing and fencing solutions for agents.
Canyon Road builds the enforcement plane for AI agents. AgentSH enforces at the runtime, Beacon on the endpoint, and Watchtower governs and distributes policy across the fleet. The framework referenced here is Anthropic's Zero Trust for AI Agents, published May 2026.
← All postsBuilt by Canyon Road
We build Beacon and AgentSH to give security teams runtime control over AI tools and agents, whether supervised on endpoints or running unsupervised at scale. Policy enforced at the point of execution, not the prompt.
Contact Us →